Faster Is Not Always Better: Choosing the Right PostgreSQL Insert Strategy in Python (+benchmarks)
PostgreSQL is fast. Whether your Python code can or should keep up depends on context. This article compares and benchmarks various insert strategies, focusing not on micro-benchmarks but on trade-offs between safety, abstraction, and throughput and choosing the right tool for the job.


This article demonstrates that it's perfectly possible to insert 2M records per second into Postgres. Instead of chasing micro-benchmarks, in this article we'll step back to ask a more important question:
Which abstractions actually fits our workload?
We'll look at 5 ways to insert data into Postgres using Python. The goal is not to look just at insert speeds and crown a winner but to understand the trade-offs between abstraction, safety, convenience and performance.
In the end you'll understand:
- the strengths and weaknesses of ORM, Core and driver-level inserts
- when performance actually matters
- how to choose the right tool without over-engineering
Why fast inserts matter
High-volume insert workloads show up everywhere:
- loading millions of records
- syncing data from external APIs
- backfilling analytics tables
- ingesting events or logs into warehouses
Small inefficiencies compound quickly. Turning a 3-minute insert job into a 10-second one can reduce system load, free up workers and improve overall throughput.
That said, faster does not automatically mean better. When workloads are small sacrificing clarity and safety for marginal gains rarely pays off.
Understanding when performance matters and why is the real goal.
Which tool do we use to insert with?
To talk to our Postgres database we need a database driver. In our case this is psycopg3 with SQLAlchemy layered on top. Here's a quick distinction:
Psycopg3 (the driver)
psycopg3 is a low-level PostgreSQL driver for Python. This is a very thin abstraction with minimal overhead that talks to Postgres directly.
The trade-off is responsibility: you write SQL yourself, manage bathing and handle correctness explicitly.
SQLAlchemy
SQLAlchemy sits on top of database drivers like psycopg3 and provides two layers:
1) SQLAlchemy Core
This is the SQL abstraction and execution layer. It is database-agnostic which means that you write Python expressions and Core will translate them into SQL in the correct database-dialect (PostgreSQL / SQL Server / SQLite) and safely binds parameters.
2) SQLAlchemy ORM
ORM is built on top of Core and abstracts even more. It maps Python classes to tables, tracks object state and handles relationships. The ORM is highly productive and safe, but all that bookkeeping introduces overhead, especially for bulk operations.
In short:
All three exist on a spectrum. On one side there's ORM, which takes a lot of work out of your hands an provides a lot of safety at the cost of overhead. On the other side there's the Driver is very bare-bones but provides maximum throughput. Core is right in the middle and gives you a nice balance of safety, performance and control.
Simply said:
- ORM helps you use the Core more easily
- Core helps you use the Driver more safely and database-agnostic
The benchmark
To keep the benchmark fair :
- each method receives data in the form its designed for
(ORM objects for ORM,dictionaries for Core, tuples for the Driver) - only the time spent moving data from Python into Postgres is measured
- no method is penalized for conversion work
- The database exists in the same environment as our Python script; this prevents out benchmark from begin bottle-necked by upload speed e.g.
The goal is not to "find the fastest insert" but to understand what each method does well.
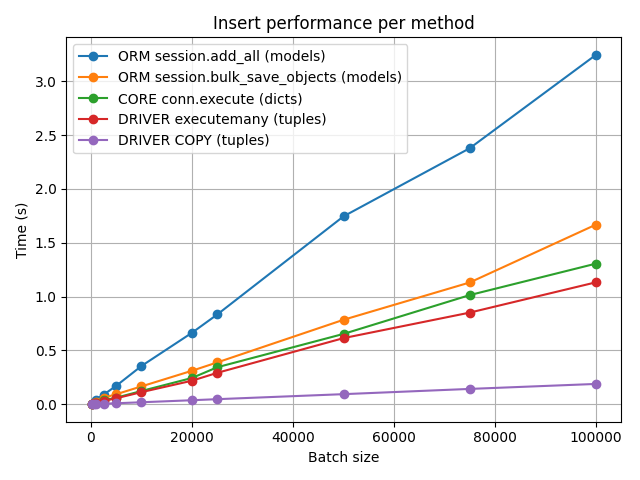
As expected, the low-level Driver has the best throughput, clocking in at roughly half a million records per second. The ORM is around 6 to 7 times slower and the core fits nicely in between. In the coming chapter we'll check out the trade-offs.
1) Faster is always better?
What is better? A Ferrari or a Jeep?
This depends on the problem you're trying to solve.
If you're traversing a forest go with the Jeep. If you want be the first across the finish line, the Ferrari is a better alternative.
The same applies with inserting. Shaving 300 milliseconds off a 10-second insert may not justify extra complexity and risk. In other cases, that gain is absolutely worth it.
In some cases, the fastest method on paper is the slowest when you account for:
- maintenance cost
- correctness guarantees
- cognitive load
2) What is your Starting Point?
The right insertion strategy less on row count and more on what your data already looks like
The ORM, Core and the driver are not competing tools. They are optimized for different purposes:
| Method | Purpose |
|---|---|
ORM (add_all) |
Business logic, correctness, small batches |
ORM (bulk_save_objects) |
ORM objects at scale |
Core (execute) |
Structured data, light abstraction |
Driver (executemany) |
Raw rows, high throughput |
Driver (COPY) |
Bulk ingestion, ETL, firehose workloads |
An ORM excels in CRUD-heavy applications where clarity and safety are most important. Think of websites and API's. Performance is usually "good enough" and clarity matters more.
Core shines in situations where you want control without writing raw SQL. Think data ingestion, batch jobs, analytics pipelines and performance-sensitive services like ETL jobs.
You know exactly what SQL you want but you don't want to manage connections or dialect differences yourself.
The Driver is optimized for maximum throughput; extremely large writes like writing millions of rows for ML training sets, bulk loads, database maintenance or migrations or low-latency ingestion services.
The driver minimizes extraction and python overhead and gives you the highest throughput. The downside is that you have to manually write SQL, making it easy to make mistakes.
3) Don't mismatch abstractions
The ORM isn't slow. COPY isn't magic
Performance problems appear when we force data through an abstraction it's not designed for:
- Using Core with SQLAlchemy ORM objects – >slow due to conversion overhead
- Using ORM with tuples – >awkward and brittle
- ORM bulk in ETL process – >wasted overhead
Sometimes dropping to a lower level can actually reduce performance.
When to choose which?
Rule of thumb:
| Layer | Use it when… |
|---|---|
| ORM | You are building an application (correctness and productivity) |
| Core | You are moving or transforming data (balance between safety and speed) |
| Driver | You are pushing performance limits (raw power and full responsibility) |
Conclusion
In data and AI systems, performance is rarely limited by the database. It is limited by how well our code aligns with the shape of the data and the abstractions we choose.
ORM, Core and Driver-level APIs form a spectrum from high-level safety to low-level power. All are excellent tools when used in the context they are designed for.
The real challenge isn't knowing which is fasted, it's in selecting the right tool for you situation.
I hope this article was as clear as I intended it to be but if this is not the case please let me know what I can do to clarify further. In the meantime, check out my other articles on all kinds of programming-related topics.
Happy coding!
— Mike
P.s: like what I'm doing? Follow me!



