Dramatically improve your database insert speed with a simple upgrade
4 levels of creating blazingly fast database connections in Python

4 levels of creating blazingly fast Python database connections
Uploading data to your database is easy with Python. Load your data into a Pandas dataframe and use the dataframe.to_sql() method. But have you ever noticed that the insert takes a lot of time when working with large tables? We don’t have time to sit around, waiting for our queries to finish!
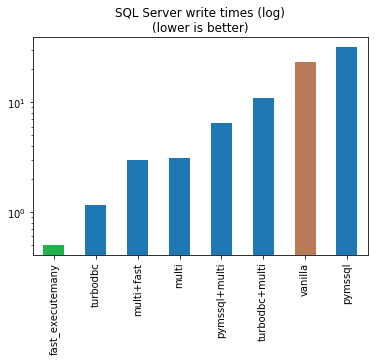
With a few tweaks you can make inserts A LOT faster. Compare the write times of the brown (default to_sql() method) with the green bar (our goal). Also notice that the vertical axis is on a logarithmic scale! At the end of this article you’ll be able to perform lightning fast database operations. Ready? Lets go!
Goals and steps
We’ll work towards the superfast insertion method in two steps. The first part focusses on how to properly connect to our database, the second part will explore 4 ways to insert data in ascendingly fast order.
1. Connecting to our database
In order to communicate with any database at all, you first need to create a database-engine. This engine translates your python-objects (like an Pandas dataframe) to something that can be inserted into databases. In order to do so it needs to know how it can access your database. This is what a connection string is used for. We’ll first create a connection string and then use this to create our database engine.

1.1 Create a connection string
The connection string contains information about the type of database, odbc-driver, and the database credentials we need to access the database.constring = "mssql+pyodbc://USERNAME:PASSWORD@DATABASESERVER_IP/DATABASENAME?driver=SQL+Server+Native+Client+11.0"
In the example above we create a string for connecting to a Microsoft SQL Server database. As you can see we specify our database credentials (username, password, the IP of our database server and the name of our database server), as well as the driver we are using. The format of a connection string differs per database, check out connectionstrings.com for an overview of what your connection string should look like.
About drivers: The driver needs to match the version of the database you’re using. In the example above we use MS SQL Server 2011 so we need a SQL Server Native Client 11 Driver. This driver needs to be in stalled on the machine you’re running your Python scripts on. Check out which drivers are installed by searching for ‘ODBC Data Sources’ (under the drivers tab). If your required driver is not installed you can easily download it (e.g. https://www.microsoft.com/en-us/download/details.aspx?id=36434).
1.2 Creating a database engine with our connection string
Once the connection string is valid it is easy to create the database engine. I usually create mine like below.
import sqlalchemy
dbEngine = sqlalchemy.create_engine(constring, connect_args={'connect_timeout': 10}, echo=False)Setting echo to True allows you to see all the queries that are executed. If you set the echo to the string ‘debug’ the result rows will be printed as well.
1.3 Testing our database engine
Use the little script below to test your connection. If all went well it should print that the engine is valid. If something went wrong it’ll print the error.try:
with dbEngine.connect() as con:
con.execute("SELECT 1")
print('engine is valid')
except Exception as e:
print(f'Engine invalid: {str(e)}')
2. Four levels of fast insertion methods
Now that we are able to connect to our database we can start inserting data into the database. We’ll explore 4ways of inserting data, ending with the fastest. At the end of this article you’ll find a detailed summary of pandas’s to_sql method.

2.1 The vanilla to_sql method
You can call this method on a dataframe and pass it the database-engine. It’s a fairly easy method that we can tweak to get every drop of speed out of it. In the example below we create a dataframe and just upload it.import pandas as pd# 1. Create a dataframe
df = pd.DataFrame({'numbers': [1, 2, 3], 'colors': ['red', 'white', 'blue']})
print(df.head())# dataframe looks like:
numbers colors
0 1 red
1 2 white
2 3 blue# 2. Upload this dataframedf.to_sql(con=dbEngine, schema="dbo", name="colortable", if_exists="replace", index=False)
As you can see we only have to specify our connection (our databaseEngine we’ve created earlier), in which schema we want to put our new table and our new tablename. In addition we can determine what to do if the specified schema.tablename already exists (in our case replace) and wether we want to put an index on the table (see further for a complete list of parameters).
The example above is the easiest way of inserting data but also the slowest. The problem is that we write the entire dataframe all at once, creating an insert statement for each record. On a small table, like our color table, this isn’t a huge problem but on large tables it definitely is.
2.2 Chunking
Our code will run a bit better if we add a chunksize. This will write the data in batches of the specified chunksize, saving a lot of memory.
df_large.to_sql(con=dbEngine, schema="dbo", name="largetable", if_exists="replace", index=False, chunksize=1000)Still this method creates an insert-statement for each record in our table which is still very slow.
2.3 Multi-insert
Adding the ‘multi’-method will improve the insertion speed a lot. In stead of writing a insert statement per record we can now send multiple rows in one statement. The databast can process amultiple records in one operation in stead of an operation per record.
IMPORTANT: this method will not work and is not necessary for a Microsoft SQL Server database. Please see method 4.
df_target.to_sql(con=dbEngine, schema="dbo", name="targettable", if_exists="replace", index=False, chunksize=1000, method='multi')The ideal chunksize depends on your table dimensions. A table with a lot of columns needs a smaller chunk-size than a table that has only 3.
This is the fasted way to write to a database for many databases. For Microsoft Server, however, there is still a faster option.
2.4 SQL Server fast_executemany
SQLAlchemy 1.3 provides us with the fast_executemany option in creating the dbEngine for SQL server. This method is the fastest way of writing a dataframe to an SQL Server database.
dbEngine = sqlalchemy.create_engine(constring, fast_executemany=True, connect_args={'connect_timeout': 10}, echo=False)df_target.to_sql(con=dbEngine, schema="dbo", name="targettable", if_exists="replace", index=False, chunksize=1000)In the code above you see that we have to adjust our databaseEngine a bit; we have to add the fast_executemany option. That’s it.
Then, when we write our dataframe to the database, the only thing we have to remember is that we do not specify our method (or set method=None). This is because the fast_executemany is multi-inserted by default.

Conclusion
With these simple upgrades you now have the tools to improve your python-to-database connections. I’ve included a summary with example code and steps below. Happy coding!
-Mike
P.S: like what I’m doing? Follow me!
Overview: to_sql parameters
Below an overview and explanation of all the settings of the to_sql function.
- con (sqlalchemy engine)
the databaseconnection (sqlalchemy engine) - name (str): required
name of the table you want to write to - schema (str): Default: default database schema (dbo)
name of the schema you want to write to. - if_exists (str): Default: ‘fail’
What to do if the specified table already exists?
- ‘fail’: throws an error
- ‘append’: appends the data to the specified table
- ‘replace‘: replace the table altogether (WARNING: this is dangerous) - index (bool): Default: True
If Index is set to True it creates an extra column named ‘id’, that is indexed - index_label (str or sequence): Default: None
Column label for the index columns. Default None. - chunksize (int): Default: None
Write rows in batches of size [chunksize]. This is a good idea if you have a lot of records that need to be uploaded. This saves memory. If None: writes all rows at once - dtype (dict or scalar): Default none
Specify datatypes
If scalar is specified: applies this datatype to all columns in the dataframe before writing to the database. To specified datatype per column provide a dictionary where the dataframe columnnames are the keys. The values are sqlalchemy types (e.g. sqlalchemy.Float etc) - method (str): Default None
Controls the SQL insertion clause
- None: uses standard SQL insert clause (one per row)
- ‘multi’: passes multiple values to a single Insert clause.



