Getting started with Cython: How to perform >1.7 billion calculations per second in Python
Combine the ease of Python with the speed of C

The main advantage of Python is that it is very developer-friendly and easy to pick up. These design choices have a major downside, though; they cause Python to execute significantly slower than some other languages. This article will show you how to eat your cake and have it too. We’re going to take the bottleneck out of our Python code and use Cython to speed it up extremely. I can strongly recommend reading this article before continuing to get a clear idea of the problem we’re trying to solve. Cython will help us to:
- use Python-like syntax to write code that Cython then will generate C-code with. We won’t have to write in C ourselves
- compile the C-code and package it into a Python module that we can import (just like
import time) - improve execution speeds of our program >70x
- brag to colleagues about our superfast code
I’ve split this article into 4 parts: First, we install dependencies and setup in part A. Then, in part B we just focus on getting Cython code to run Python. Once this is done we optimize our Cython code in part C using a handy built-it tool that’ll tell you exactly where the bottlenecks in your code are. Then, in part D we’ll squeeze out the last bit of speed by multiprocessing our module, resulting in over 1.7 billion calculations per second!
Let’s code!
By using Cython to create a Python module and multiprocessing the resulting function we’ve increased execution speeds from 25 thousand e/ms to 1.75 million e/ms. This is a speed increase of 70x!
Before we begin
Creating a Cython package has some enormous benefits but it also takes a bit more effort than your regular Python programming. Think about the following before Cythonizing every last line of your code.
- Make sure your code is slow for the right reason.
We can’t write code that waits faster. I recommend first glancing through this article because it explains why Python is slow, how it works under the hood and how you can work your way around certain bottlenecks. This way you’ll understand more how Cython is a very good solution to our slowness. - Is concurrency the problem?
Can your problem be solved by using threads (like waiting for an API)? Maybe running code in parallel over multiple CPUs helps your speed by multiprocessing? - Are you a good C programmer or just interested in how Python and C work together? Check out this article about how Python modules are written in C (how Python uses C-code).
- Make sure to use a virtual environment. This is not required by Cython but it is best practice.
Part A — Installation and setup
Installation is very easy.pip istall Cython
To showcase how Cython can speed up CPU-heavy tasks we’ll use a simple example: we’re going to Cythonize a function that counts the number of prime numbers within a given range. The Python code for this looks like this:
Note that this is hardly the most efficient way to calculate primes but that’s not important for now. We just want a function that calculates a lot.

Part B — Creating, packaging, and importing
First, we’re going to create a very simple Cython function that closely resembles the one we’ve written in Python. The goal of this part is to:
- create the function
- compile and package the C-code in a Python module
- import and use our function.
Further down we’ll optimize the function to achieve mindblowing speed.
1. Creating the Cython function
Let’s create a new file called primecounter.pyx and:
- copy the
prime_count_vanilla_rangefunction from the previous part into the file - Rename the function we’ve just pasted to
prime_counter_cy.
For now, we’ll just run the Python code in Cython. This is possible because Cython is a superset of Python; anything you can do in Python, you can do in Cython.
Just copying the function should already give is a nice speedup because the code is compiled now. Before we can check that, however, we have to get the code into Python using a module.
2. Compiling and packaging into a Python package
The next step is to instruct Cython to take the pyx-file, compile it into C, and stuff that code into a Python module that we can import and use in our Python code. For this, we’ll need a simple setup.py script that defines what and how we want to package. This is what it looks like:
You might be familiar with the setup.py script: it is used when creating your own Python package. More on creating your own package here (public package) and here (private package).We simply define a list of extensions and pass it to the setup function. In the Extension we give our module a name. This way we can import primes and then primes.prime_counter_cy(0, 1000) later. First, we’ll create and install the module. The code below acts like pip install primes:python setup.py build_ext --inplace
You can also use CythonBuilder for compiling, building and packaging your Cython code; check it out here.
Troubleshooting
Cython will compile the pyx into a C-file which we’ll include in the module. For this compilation process, it needs a compiler. If you receive a message like Microsoft Visual C++ 14.0 or greater is required it means you don’t have a compiler. You can solve this by installing C++ build tools that you can download here.
3. Importing and using our function
Now that our module is compiled, packaged, and installed we can easily import and use it:import primes
print(primes.prime_counter_cy(0, 1000))
# >> will correctly print out 168
When we time the Python function and Cython function we already see a nice speedup:Finding primes between 0 and 1000
Total number of evaluations required = 78 thousand
[py] 2.92ms (25k per ms)
[cy] 1.58ms (42k per ms)
Even though we’ve merely copied the function and have not spent a single second optimizing it, it's still faster just because the code is compiled.
Notice that the number of evaluations indicates how many numbers need to be compared for the function to find all the primes in the range. They consist of multiple calculations which make this speedup even more impressive. Check out how it’s calculated here.
Now the fun part begins: let’s start optimizing and see how much speed we can squeeze out of our machine!

Part C — Optimizing our Cython function
We’re going to tweak the function in the pyx file to speed it up. Let’s first look at the result so that we can go through it.
We’ve added types for variables and for the function itself. A lot of these additions enable C to compile our program so that we don’t get bogged down by the Python Interpreter. Check out this article for more information on why the interpreter slows execution down so much how to speed it up (spoiler alert: writing a Cython module is one of them!)
When a variable in Cython is not typed we fall back to how Python handles variables; checking each of them with the interpreter and storing them in a PyObject (again, check out the article). This is very slow so by typing our variables we let C handle them, which is blazingly fast.
Adding types
In line 1 we define prime_counter_cy as a function of type cpdef. This means that both Python and C can access the function. In line 1 we write int range_from. This way the compiler knows the data type of range_from is an integer. Because we know which data to expect we avoid a lot of checks. The same goes on in line 3 where we cdef an integer named prime_count. In the two lines below we define num and divnum. The special thing about these two integers is that they don’t have a value yet, their value only gets set in lines 7 and 8.
Just adding types increased performance a lot. Check it out:Finding primes between 0 and 50k
Total number of evaluations required = 121 million
[py] 4539ms ( 27k /ms)
[cy] 2965ms ( 41k /ms)
[cy+types] 265ms (458k /ms)
We go from a little over 4.5 seconds to a quarter of a second. This is a speed increase of 17x just adding some types.
Optimizing further using annotations
All of our variables are defined; how can we optimize further? Remember the setup.py? In line 8 (see above) we’ve called the cythonize function with annotate=True. This creates an HTML file in the same directory as our pyx file.
When we open that file in the browser we see our code annotated with yellow lines that indicate how close to Python the line of code is. Bright yellow means that it’s a lot like Python (read: slow) and white means that it’s closer to C (fast). This is what it looks like when we open our primecounter.html in a browser:
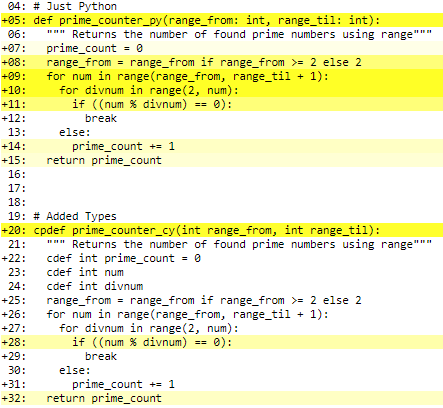
In the image above you can see what adding types does for the code. You can also click on each line to see the resulting C-code. Let’s click on line 28 to see why it’s not completely white.
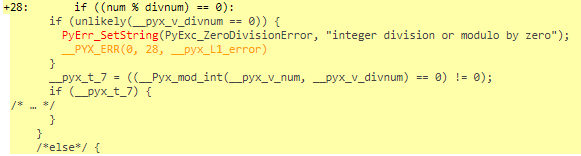
As you can see in the image above, Python checks for a ZeroDivisionError. I don’t think this is necessary because the range that calls divnum starts at 2.
Avoiding unnecessary checks
So let’s optimize further! We’re adding a decorator to our function that tells the compiler to avoid the ZeroDivisionError-check. Only do this when you’re very sure of your code because avoiding checks means extra risks of your program failing:
There are many of these so-called compiler directives that you can apply. Many of them are interesting when it comes to loops. Read more on these compiler directives here.
Checking out our annotations:
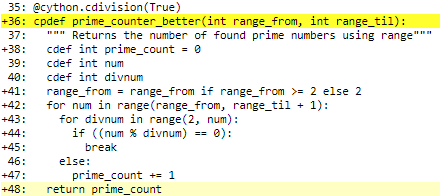
Finding primes between 0 and 50k
Total number of evaluations required = 121 million
[py] 4539ms ( 27k /ms)
[cy] 2965ms ( 41k /ms)
[cy+types] 265ms (458k /ms)
[cy-check] 235ms (517k /ms)
This small directive improved execution times even more!

Part D — Even more speed
So our function is pretty optimized now, it runs almost entirely in machine code. How can we squeeze out even more speed? If you’ve read this article you might have an idea. Our code still runs on one CPU while my laptop has 12 so why not use more?
The code above creates a ProcessPool (again; read this article) that will divide all jobs over all of my available CPUs. In line 3 we use a function to divide the start and endnumber over the number of workers. If we want 0 till 100 with 10 workers, it generates 0 till 9, 10 till 19, 20 till 29, etc.
Next, we create the job by submitting it to the threadpoolexecutor. In the last record, we retrieve the result of each job and sum up the results to get the number of prime numbers.
Is it worth the investment of setting up?
As this article explains applying multiple processes takes a little investment; it takes a while before the processes are created. If benchmark our new multiprocessed function with the normal one it is even slower when we examine the first 10k numbers:Finding primes between 0 and 10k
Total number of evaluations required = 5.7 million
[py] 246ms ( 23k /ms)
[cy] 155ms ( 37k /ms)
[cy+types] 14ms (423k /ms)
[cy-check] 12ms (466k /ms)
[cy-mp] 201ms ( 29k /ms)
Yikes, that’s not fast at all. Let’s see what happens when we check out the first 50.000 numbers:finding primes between 0 and 50k
Total number of evaluations required = 121 million
[py] 4761ms ( 25k /ms)
[cy] 3068ms ( 40k /ms)
[cy+types] 304ms (399k /ms)
[cy-check] 239ms (508k /ms)
[cy-mp] 249ms (487k /ms)
Notice that we are not making up for the investment of setting up processes by the increased calculation speed.
The final test
For the final test, we’re going to find all primes between 0 and 200k. Notice that we already waiting multiple seconds for the first two methods. Also notice that increasing our range increases the total number of required evaluations exponentially. For this reason, we’re only benchmarking the Cython methods:finding primes between 0 and 200k
Total number of evaluations required = 1.7 billion
[cy+types] 3949ms ( 433k /ms)
[cy-check] 3412ms ( 502k /ms)
[cy-mp] 978ms (1750k /ms)
And here we see our result; we are executing 1.75 million evaluations per millisecond. Notice that the number of actual operations is even higher!
By using Cython to create a Python module and multiprocessing the resulting function we’ve increase execution speeds from 25k e/ms to 1.75 million e/ms. This is a speed increase of 70x!

Our code has transformed from a slow car to a hypersonic airplane (image by NASA on Unsplash)
Conclusion
With this article I hoped to have shown that you can extend your Python code with a little Cython to achieve incredible speed increases, combining the ease of coding in Python with the incredible speeds of compiled C. Want to
I hope everything was as clear as I hope it to be but if this is not the case please let me know what I can do to clarify further. In the meantime, check out my other articles on all kinds of programming-related topics like these:
- Why Python is so slow and how to speed it up
- Write your own C extension to speed up Python x100
- Advanced multi-tasking in Python: applying and benchmarking threadpools and processpools
- Virtual environments for absolute beginners — what is it and how to create one (+ examples)
- Create and publish your own Python package
- Create Your Custom, private Python Package That You Can PIP Install From Your Git Repository
- Create a fast auto-documented, maintainable, and easy-to-use Python API in 5 lines of code with FastAPI
- Dramatically improve your database insert speed with a simple upgrade
Happy coding!
— Mike
P.S: like what I’m doing? Follow me!




