Multi-tasking in Python: Speed up your program 10x by executing things simultaneously
Step-by-step guide to apply threads and processes to speed up your code

This article focuses on speeding up your program by making it do multiple things at the same time. We don’t have to idle while our program waits for and API response e.g; we can do something else in that same time! We’ll also get into how to apply more CPU’s to speed up calculation times. At the end of this article you’ll:
- understand the difference ways of multi-tasking
- know when to apply a which technique
- be able to speed up your own code by using the code examples
Before we begin I’d strongly suggest to check out the article below. It explains how Python works under the hood and why it isn’t as fast as other languages. Also it reveals why isn’t Python multi-threaded to begin with? You’ll have a better understanding of what the problem we’re trying to solve in this article. Let’s code!

Threads and processes
Python can multi-task in two ways: threading and multiprocessing. On the surface they appear very alike but are fundamentally different. In the parts below we’ll examine both by using two simple metaphors. Our goal is to get an understanding of the differences between threads and processes so that we know when to use which.
Threading is like making breakfast
Let’s make some breakfast: we’ll need a boiled egg, some toast and a cup of coffee so we have 4 tasks:
- toast bread
- boil water
- boil egg
- switch on the coffee maker

How would you go about this? One way is to perform each task sequentially; first toast bread, then boil water and an egg an then switch on the coffee maker. Although this process is pretty understandable, in the end it just leaves us with some cold toast, a cold egg and a hot cup of coffee. Alternatively we could perform some tasks simultaneously; we’ll switch on the coffee maker and toaster and boil some water at the same time.
Let’s simulate this with some code.
We’ll run this code sequentially (one after the other) like this:toast_bread()
boil_water_and_egg()
make_some_coffee()
Making breakfast sequentially will take around 17.5 seconds. This involves a lot of waiting! Let’s multitask using threads:
The code is pretty straight-forward: we’ll create some tasks and append all of them to a list. Then we’ll start each thread in the list and wait for all of them to finish (this is what t.join() does). Making breakfast concurrently takes around 8 seconds!
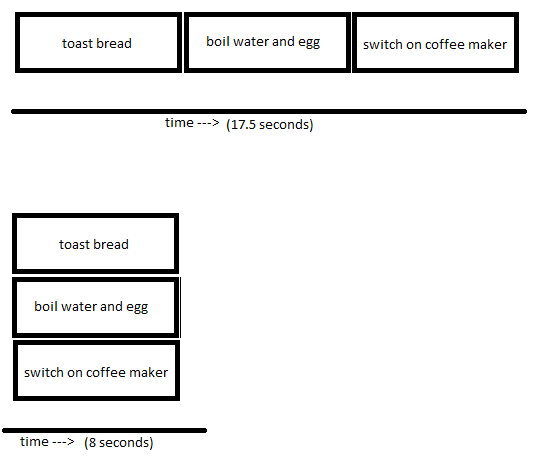
The main take-away is that if there’s a lot of waiting involved (typical in I/O tasks like downloading data, API requests, writing files..) we can use threads to multi-task. Later on in this article we’ll examine why threads are the best option for I/O-tasks.
Multiprocessing is like making your homework
When we apply the same breakfast-making principle to making our homework we run into a problem; doing math homework is a task that needs constant attention; we can’t start it and wait for it to finish! In order to do multiple subjects of homework at the same time we would need to clone ourselves, right? Multiprocessing does exactly that.

Let’s first translate our homework example to some code. We’ll simulate doing our homework with some CPU-intensive processing; adding up all numbers from 0 to 100 million:
These are CPU-intensive functions; we have to perform a lot of calculations. We’ll first execute these functions sequentially, then threaded (same code as in the previous part) and then using the code below to spawn processes. Notice that the code looks a lot like the threading-code from the previous part.
The benchmaks:
- sequentially: 14.22 seconds
- using threads: 13.89 seconds
- using processes: 6.00 seconds
You’ll see that using processes speeds up executing by quite a lot! The reason for this is that we can use more CPU’s.
In this example we have to to 300 million * 3 calculations. Threading this doesn’t speed it up because it’s still one CPU that has to perform 300 million calculations. When using processes however, we spawn a brand-new instance of Python on a different CPU. In other words we’ll use 3 CPU’s that can perform 100 million calculations each!
Summary
Threads are for making-breakfast-like tasks: it involves a lot of waiting so one ‘person’ (or CPU) can do thing simultaneously. Processes are for ‘thinking-tasks’; they need you to be there to do the heavy work. Multiprocessing is like creating a clone of yourself so it can do other things while you are working on your task.
Threading and multiprocessing under the hood
Now that we have a clearer understanding of how threads and processes work, let’s talk a bit about the differences between the two.

The GIL — why threads are more suitable for I/O
As discussed threads are suitable for I/O tasks whereas processes are suitable for CPU-heavy tasks. The reason for this is Python’s infamous GIL; the Global Interpreter Lock. This lock ensures that Python runs single-threaded, blocking other processes that do not hold on to the lock. Many I/O processes release the GIL while idle, making threading possible. Check out this article to understand why Python applies the GIL.
In the homework-example threading makes no sense because the task involved is not an I/O-task. Because of the GIL only one thread can execute at any moment so it offers no speed-ups. When multiprocessing we create a fresh instance of Python which has its own GIL. This way processes run in parallel, speeding up the executing of our program significantly.
Processes can’t share resources
The main one is that processes can’t share resources while threads can. This is because a process works with multiple CPU’s whereas a thread is just one CPU going back and forth between multiple threads.
You can think of threading as a single CPU that first executes a few lines of code in thread1, then it executes some lines in thread2, then moves on to thread3. Then it executes the next line in thread1, then thread2 etc. Threading executes multiple tasks concurrently; one worker that switches between tasks. For the user it looks as though things happen simultaneously, this isn’t technically so.
When you spawn a new process a whole new instance of python is created and allocated to a different CPU. This is the reason why two processes cannot share a common resource. Processes run in parallel; there are multiple workers that work on multiple tasks simultaneously.
Overhead
Processes take a little more time to spawn. This is the reason the homework example is not three times faster but slightly less; first we’ll have to spawn the processes before we can benefit from the parallelism.
Even more speed
Multi-tasking can solve a lot of speed-issues in Python but sometimes it’s just not enough. Check out this or this article that show you how to compile a small part of your code for a 100x speed increase.

Conclusion
Threading and multiprocessing can be used to speed up the execution of your code in many, many cases. In this article we’ve explored what threads and processes are, how they work and when to use which. Don’t forget to check out this article on how to apply pools and for benchmarks!
If you have suggestions/clarifications please comment so I can improve this article. In the meantime, check out my other articles on all kinds of programming-related topics like these:
- Why Python is slow and how to speed it up
- Advanced multi-tasking in Python: applying and benchmarking threadpools and processpools
- Write you own C extension to speed up Python x100
- Getting started with Cython: how to perform >1.7 billion calculations per second in Python
- Create a fast auto-documented, maintainable and easy-to-use Python API in 5 lines of code with FastAPI
- Create and publish your own Python package
- Create Your Custom, private Python Package That You Can PIP Install From Your Git Repository
- Virtual environments for absolute beginners — what is it and how to create one (+ examples)
- Dramatically improve your database insert speed with a simple upgrade
Happy coding!
— Mike
P.S: like what I’m doing? Follow me!




