Why Python is so slow and how to speed it up
Take a look under the hood to see where Python’s bottlenecks lie

In this article we’ll discover that Python is not a bad language that is just very slow. It is optimized for the purpose it is built: easy syntax, readable code and a lot of freedom for the developer. These design choices, however, do make Python code slower than other languages like C and Java.
Understanding how Python works under the hood will show us the causes of why it’s slower. Once the causes are clear we can work our way around it. After reading this article you’ll have a clear understanding on:
- how Python is designed and works under the hood
- why these design choices affect execution speed
- how we can work around some of these bottlenecks to increase the speed of our code significantly
This article is split in three parts. In part A we take a look at how Python is designed. Then, in part B see how and why these design choices affect speed. Finally, in part C we’ll learn how to work around the bottlenecks that result from Python’s design and how we can speed up our code significantly.
Let’s go!
Part A — Python’s design
Let’s start off with a definition. Wikipedia describes Python as:
Python is an interpreted, high-level, general-purpose programming language. It is dynamically typed and garbage-collected.
Believe it or not, you’re going to understand the two sentences above after you’ve read this article. This definition provides a nice glance of Python’s design. High-level, interpreted, general-purpose, dynamic typing and the way garbage is collected take away a lot of hassle from the developer.
In the next parts we’ll go through these elements of design, explain what it means for Python’s performance and conclude with a practical example.

Slowness vs waiting
First let’s talk about what we’re trying to measure when we say “slow”. Your code can be slow for a multitude of reasons but not all of them are Python’s fault. Let’s say that there are two types of tasks:
- I/O-tasks
- CPU-tasks
Examples of I/O tasks are writing a file, requesting some data from an API, printing a page; they involve waiting. Although they cause your program to take more time to execute, this is not Python’s fault. It’s just waiting for a response; a faster language cannot wait faster. This kind of slowness is not what we’re trying to solve in this article. As we’ll see later we can thread these types of tasks (also described in this article).
In this article we figure out why Python executes CPU-tasks more slowly than other languages.
Dynamically typed vs Statically typed
Python is dynamically typed. In languages like C, Java or C++ all variable are statically typed, this means that you write down the specific type of a variable like int my_var = 1;.
In Python we can just type my_var = 1. We can then even assign a new value that is of a totally different type like my_var = “a string". We’ll see how this works under the hood in the next chapter.
Although dynamic typing is pretty easy for the developer, it has some major downsides as we’ll see in the next parts.
Compiled vs Interpreted
Compiling code means to take a program in one language and convert it into another language, usually a lower level than the source. When you compile a program written in C you convert the source code to machine code (which are actual instructions for the CPU), after which you can run your program.
Python works a little different:
- Source code is not compiled into machine code but into platform-independent bytecode. Like machine code, bytecode are also instructions but in stead of being executed by the CPU they are executed by an interpreter.
- Source code gets compiled while running. Python compiles files as needed in stead of compiling everything before running the program.
- The interpreter analyzes the bytecode and translates it to machine code.
Python has to compile into bytecode because it is dynamically typed. Because we don’t specify the type of a variable beforehand, we have to wait for the actual value in order to determine whether what we’re trying to do is actually legal (like adding two integers) before translating to machine code. This is what the interpreter does. In statically typed, compiled languages the compilation and interpretation occurs before running the code.
In summary: code is slowed down by the compilation and interpretation that occurs during runtime. Compare this to a statically typed, compiled language which runs just the CPU instructions once compilated.
It’s actually possible to extend Python with compiled modules that are written in C. This article and this article demonstrates how you can code your own extension in C to speed up your code x100.
Garbage collection and memory management
When you create a variable in Python, the interpreter automatically picks out a spot in memory that is large enough for the value of the variable and stores it there. Then, when the variable is not needed anymore, the slot of memory gets freed again so that other processes can use it again.
In C, the language where Python is written in, this process is not automated at all. When you declare a variable you need to specify its type so that the correct amount of memory can be allocated. Also garbage collection is manual.
So how does Python keep track of which variable to garbage-collect? For each object Python keeps track of how many objects reference that object. If a variable’s reference count is 0 then we can conclude that the variable isn’t used and that it can be deallocated in memory. We’ll see this in action in the next chapter.
Single-thread vs multi-threaded
Some languages, like Java, allow you to run code in parallel on multiple CPU’s. Python, however, is single-threaded on a single CPU by design. The mechanism that makes sure of this is called the GIL: the Global Interpreter Lock. The GIL makes sure that the interpreter executes only one thread at any given time.
The problem the GIL solves is the way Python uses reference counting for memory management. A variable’s reference count needs to be protected from situations where two threads simultaneously increase or decrease the count. This can cause all kinds of weird bugs to to memory leaks (when an object is no longer necessary but is not removed) or, worse, incorrect release of the memory. In the last case a variable gets removed from the memory while other variables still need it.
In short: Because of the way garbage collection is designed, Python has to implements a GIL to ensure it runs on a single thread. There are ways to circumvent the GIL though, read this article, to thread or multiprocess your code and speed it up significanly.
Part B — A look under the hood: Pythons design in practice
Enough with al the theory, let’s see some action! Now that we know how Python is designed, let’s see it in action. We’ll compare the simple declaration of a variable in both C and Python. This way we can see how Python manages its memory and why its design choices result in slow execution times compared to C.

Declaring a variable in C
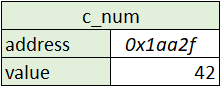
Let’s start out by declaring an integer in C called c_num.int c_num = 42;
When we execute this line of code our machine does the following:
- Allocate enough memory for an integer at a certain address (location in memory)
- Assign the value 42 to the location of the memory that’s allocated in the previous step
- Point c_num to that value
Image there now exists an object in memory that looks like this:
If we assign a new number to c_num we write the new number to the same address; overwriting, the previous value. This means that the variable is mutable.
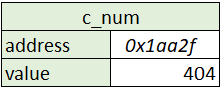
Notice that the address (or location in memory) did not change. Think of it as c_num owning a piece of memory big enough for an integer. You see in the next part that this differs from how Python works.
Declaring a variable in Python
We’ll do the exact same thing as in the previous part; declare an integer.py_num = 42
This line of code kicks of the following steps during execution:
- Create a PyObject; allocating enough memory to an address
- Set the PyObject’s typecode to integer (as determined by the interpreter)
- Set the PyObject’s value to 42
- Create a name called py_num
- Point py_numto the Pyobject
- Increment the PyObject’s refcount by 1
Under the hood the first thing that’s done is to create a PyObject. This is what is meant by the phrase ‘everything in Python is an object’. Python might have the int, str and float types but under the hood every Python variable is just a PyObject. This is why dynamic typing is possible.
Notice that PyObject is not an object in Python. It’s a struct in C that represents all Python objects. If you are interested in how this PyObject works in C check out this article where we code our own C-extension in Python that increases execution speeds x100!
The steps above create the (simplified) objects in memory below:
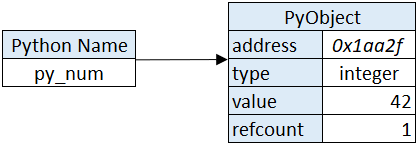
You’ll immediately notice that we execute more steps and need more memory to store an integer. In addition to the type and value, we also store the refcount for garbage collection purposes. Also you’ll notice that the variable we’ve created, py_num, doesn’t own a block of memory. The memory is owned by the newly created PyObject to which py_num points.
Technically speaking Python has no variables like C has; Python has names. Variables own pieces of memory and can be overwritten, names are pointers to a variable.
So what happens when we want to assign a different value to py_num?
- Create a new PyObject at a certain address, allocating enough memory
- Set the PyObject’s typecode to integer
- Set the PyObject’s value to 404 (the new value)
- Point py_numto the Pyobject
- Increment the new PyObject’s refcount by 1
- Decrease the old PyObject’s refcount by 1
These steps result alter the memory like in the image below:
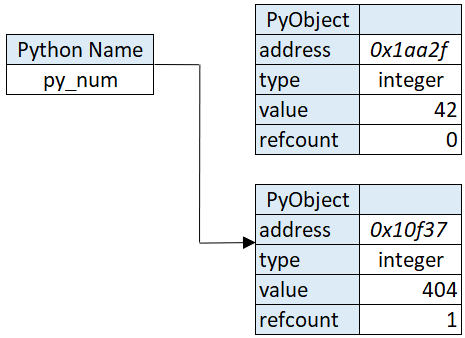
The image above will demonstrate that in stead of assigning a new value to py_num, rather we bind the name py_num to a new object. This way we can also assign a value of a different type because a new PyObject will be created every time. Py_num just points to a different PyObject. We don’t overwrite like in C, we just point to another object.
Also notice that the refcount on the old object is 0; this will make sure it gets cleaned up by the garbage collector.
Part C — How to speed things up
In the previous parts we’ve dug deep into Pythons design and have seen the consequences in action. We can conclude that the main problems for execution speed are:
- Interpretation: compilation and interpretation occurs during runtime due to the dynamic typing of variables. For the same reason we have to create a new PyObject, pick an address in memory and allocate enough memory every time we create or “overwrite” a “variable” we create a new PyObject for which memory is allocated.
- Single thread: The way garbage-collection is designed forces a GIL: limiting all executing to a single thread on a single CPU

So, with all the knowledge of this article, how do we remedy these problems? Some tips below:
- Use built-in C-modules in Python like
range() - I/O-tasks release the GIL so they can be threaded; you can wait for many tasks to finish simultaneously (more info here and here)
- Run CPU-tasks in parallel by multiprocessing (more info)
- Create and import your own C-module into Python; you extend Python with pieces of compiled C-code that are 100x faster than Python. (info)
- Not an experienced C-programmer? Write Python-like code that Cython compiles to C and then neatly packages into a Python package. It offers the readability and easy syntax of Python with the speed of C (more info)

Conclusion
If you’re still reading this the complexity and length of this article hasn’t scared you off. Kudos to you! I hope to have shed a light on how Python works under the hood and how to work around its bottlenecks.
If you have suggestions/clarifications please comment so I can improve this article. In the meantime, check out my other articles on all kinds of programming-related topics like these:
- Write you own C extension to speed up Python x100
- Getting started with Cython: how to perform >1.7 billion calculations per second in Python
- Multi-tasking in Python: speed up your program 10x by executing things simultaneously
- Advanced multi-tasking in Python: applying and benchmarking threadpools and processpools
- Create a fast auto-documented, maintainable and easy-to-use Python API in 5 lines of code with FastAPI
- Create and publish your own Python package
- Create Your Custom, private Python Package That You Can PIP Install From Your Git Repository
- Virtual environments for absolute beginners — what is it and how to create one (+ examples)
- Dramatically improve your database insert speed with a simple upgrade
Happy coding!
— Mike
P.S: like what I’m doing? Follow me!



